Survey concerning usage of OCR texts
Background
In spring of 2016 the BSB (back then part of the coordinating project) conducted a survey on the usage of OCR texts via the OCR-D-project-website which mainly addressed humanists. In total 139 researchers took part in the poll. 39 of those answers were partly illegible and some of the questions were only answered by a part of the participants.
Major findings
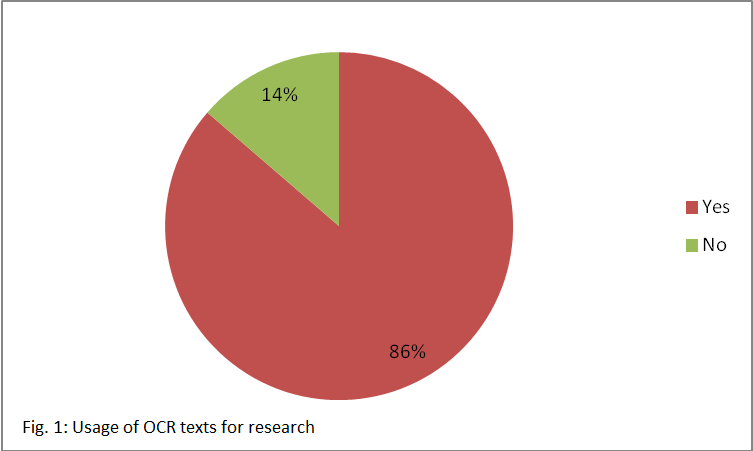
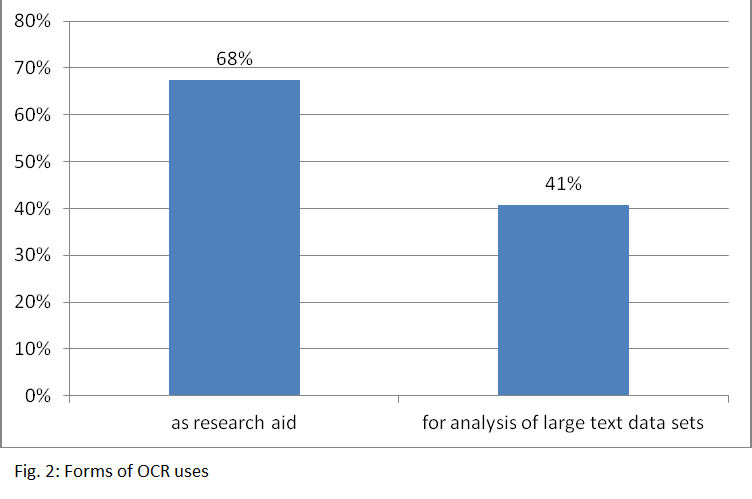
The survey shows that the great majority of the participants uses OCR texts for their research (cf. figure 1). Those texts are mainly used as search tools, but also as basis for the analysis of large amounts of text data (cf. figure 2). 60 % of the participants would also use dirty OCR texts for research purposes, whereas 40 % consider it useless data. Interestingly, only historians (87 %) show a significant preference of dirty OCR which is seen especially helpful as finding aid as one can still find information which would have been missed otherwise. Furthermore it facilitates citing by providing an initial text which can then be corrected so that the text doesn’t have to be typed completely manually. Overall however, the original image (61 %) is preferred to the OCR text (39 %) for citing, especially by librarians. Concerning the importance of versioning OCR texts there is much discord among the participating scholars. While almost three quarters of the researchers states that changes in the OCR text are important to their work, only half them wants to have access to earlier versions of OCR texts. These are mainly considered necessary for persistent quoting of the OCR text and for reproducing analyses conducted on those texts – though keeping track of all versions is rather seen as too laborious.
All in all, OCR texts are already widely used for research and also dirty OCR, as is currently the state of most OCRed early modern texts, is regarded as a valuable aid for particular parts of scientific work.